The art of randomization
06 Apr 2017We all know that drugs are used as treatments for diseases, right? But did you think about how, scientifically, it is shown that drugs actually benefits and but not harms? Before my biostats education, I was naively imagining that since we know what causes the disease and which part of the body it affects etc., scientist are producing chemicals to cure the diseases. But, of course, this was so naive and human body is so complicated, and mostly we don’t know even the causes of the diseases. Then, I learned that, clinical studies are conducted to show whether a drug works or not 1.
Let`s imagine that if anybody who developed a disease die without exception (in other words outcome of disease is invariable). Then, if we give our drug to one diseased person, and to see that he/she lives, that would be an indication for the value of drug. But we know that the outcome of disease, patients and their reaction to drugs are all vary.
So, we need to give the drug to many patients, and then analyse the results. But do we need a representative sample of the patients from whole population (for example from one country) to obtain unbiased results? Finding such people would be very hard. But still, let say we found 100 people who are representative, and give them drugs. By the way, let assume that our aim is reducing the blood pressure, so we took the number of diastolic blood pressure from 100 people before they receive the drug (baseline) and after they receive it (follow-up). So, below figure is the difference of the number of diastolic blood pressure from baseline to follow-up:
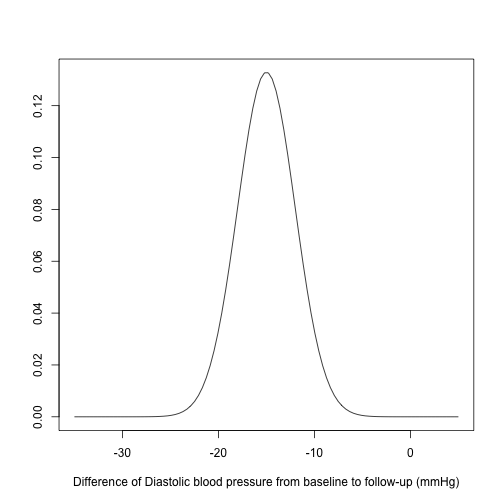
OK, results are almost all negative, that means blood pressure is decreasing (which was our aim), so we can conclude that drug works, right? Actually, no. The thing is although patients are recovered, we don’t know which of the patients who recover do so because of the drug or because they would have done so anyway. Therefore, we need another 100 patients who enter the clinical trial but do not take the drug: so-called control group (treatment group was the first one). Here, an important point is that the baseline of the treatment group and control group should be similar, otherwise the results may depend on the baseline, that mean we won`t get any reliable results.
One way to get comparable groups is that taking two representative samples from whole population, and making one group treatment group and the other control group. But this is way more costly and hard.
Another option is the randomization. If there are 200 patients who are eligible to enter the experiment, we randomly assign them to either control group or treatment group (randomized controlled trial (RCT)). Now we have comparable groups. Then, we see results like that
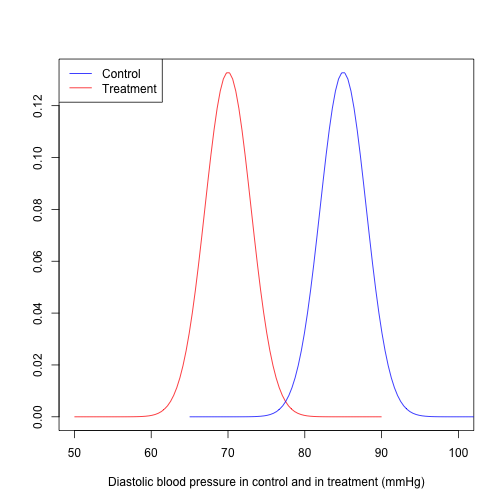
One of the coolest thing with RCTs is that we don’t need any representative sample from whole population. Let me explain why.
Below you see a diagram which explains how patients are entered to an RCT.
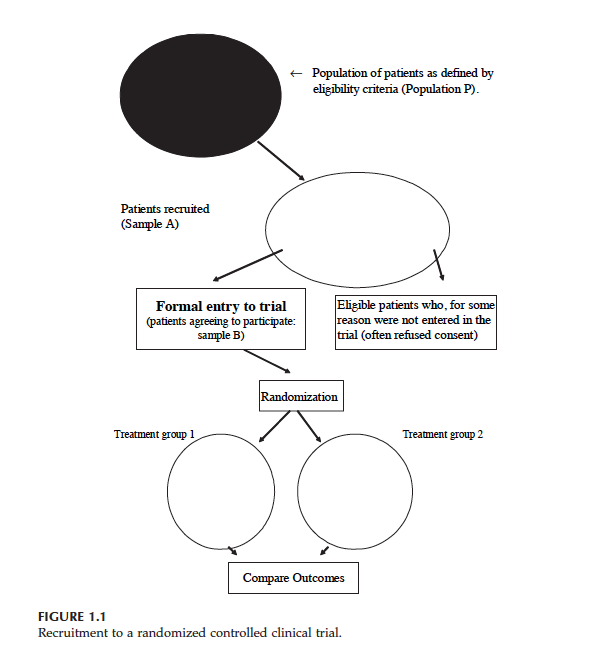
At the top you see population P. We want to know whether drug works in population P. But then, we have some patients who are eligible to trial (Sample A), lastly we have Sample B which includes the eligible patients who give their consent to enter the RCT (Treatment 1 is control group and Treatment 2 is treatment group).
Let say, the outcome measured on each individual (for example blood pressure) is a random variable . Say (if we do not give any drug to sample B) and where is true treatment effect (if we give the drug to sample B). And let say, and are mean of control group and treatment group (after randomization).
Then, and , since both control group and treatment groups are random sample from Sample B. Then, . Statistically speaking we have an unbiased estimate of treatment effect . As you see, we did not care that sample B (or A) is a random sample from population P. Even if in population P is very different from , our estimate of is still unbiased.
Another important feature of a RCT is that by design, possible confounding factors are controlled. This is the crucial difference between observational studies and RCTs. Because of these and some other important reasons, RCTs are generally considered as gold standard. But sometimes it is just not possible to conduct an RCT. For example, you wonder if there is an association between smoking and lung cancer. So what you need is that finding people, and after randomization you need to force half of them to smoke, right? But of course this is completely unethical. So in similar scenarios, and also because RCTs are more costly than observation studies, we have to make use of observational studies. Therefore, in general, when we want to generalize our results from the sample to target population, we either need the randomization (Randomized clinical trial) or representative sample (observational studies).
Lastly, there is another source of evidence which is regarded even more reliable than an RCT, and I will try to explain it in the next post.
Note: I took the diagram and definitions from the book: “Introduction to Randomized Controlled Clinical Trials” (Second edition) written by John N. S. Matthews.
-
Actually, a better question may be what is the magnitude of the treatment effect and what is the uncertainty attached to it, but this is not the main point of the post. ↩